BLOGブログ
【Tech Blog】音声認識とクラウドでのリアルタイム構文解析 - 視覚支援のDX ①
文責:浅井 健一
- 視覚支援
- 音声認識
療育 (発達支援が必要な子どもたちが、自立できるようにするための治療・教育) の現場で絵カードを使った視覚支援が行われています。発達支援が必要な子供たちは言葉で伝えられた内容を理解するより、目でみてわかることの理解が得意なので絵カードを使ってのコミュニケーションが有効だからです。
ただし、絵カードだとカードを用意する必要があり、話しながらカードを探す手間がうまれます。これを音声認識により簡単にカードを探せるようにできないかを検証するために、いくつかある音声認識の技術を調査していきたいと思います。
音声認識とは、人間の声などをコンピューターに認識させることであり、話し言葉を文字列に変換したり、あるいは音声の特徴をとらえて声を出している人を識別する機能です。最近ではクラウド上やOSのAPIで音声認識や構文解析ができるようになっています。
一昔前までは、この技術を独自で実装しようとすると、大変な時間が掛かりました。今は、OSの機能として提供されていたり、AWS(Amazon Web Services)やGCP(Google Cloud Platform)上でもAPIが解放されており、誰でも簡単に利用する事ができます。
< 全体イメージ >
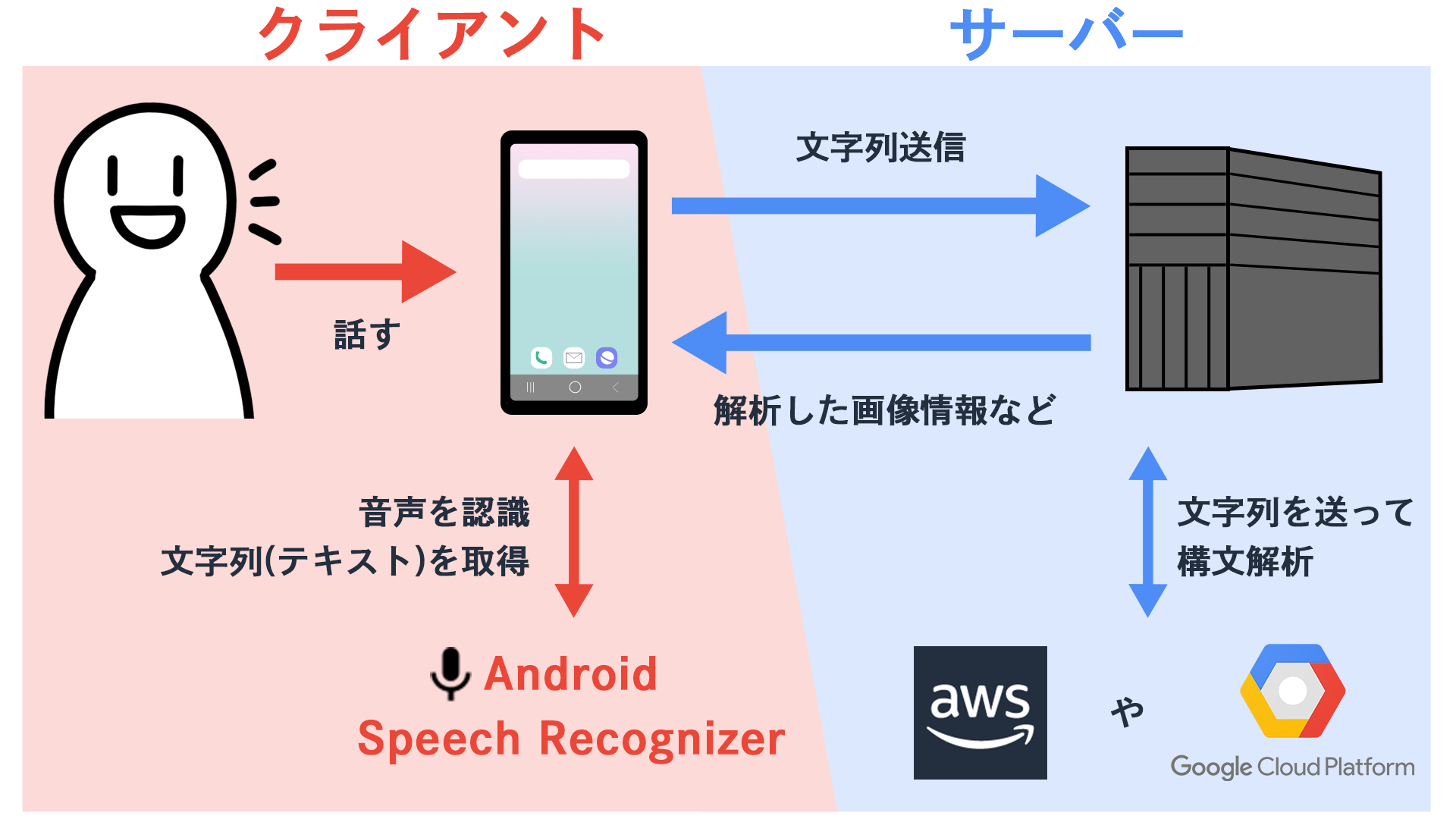
■まず音声認識部分の(Android) Speech Recognizerとは
- AndroidOSで使用できる音声入力・認識を行ってくれるAPIです。
- 話したら認識、テキスト化まで行ってくれます。
- インターネットを使用してのオンライン認識、インターネットが切れた状態のオフライン認識などがあります。
※注意点
- 認識が始まるときにピコンピコンと音が鳴り少しうるさいです。
→ Android OSの音システムが複数あるので一般的なサウンドではなく、目覚ましなどの音量システムをコードで指定するなどで対処できます。
- ネイティブ機能なのでUnityなどで使用する場合は、プラグインを実装する必要あります。
→ 難しくないので自分で実装して対処できます。
■次にリアルタイムでの構文解析にてどのようなことを実現したいのか?
< 全体イメージ >

ちょっとした会話から名詞や動詞を抜き出して登録されているキーワードへのマッチングを実現させたいと思います。
「カレーを食べます」
「公園で遊びます」
「白い車に乗ります」
「カレーとパスタ、どっちを食べる」
アップデート、サーバ管理などあまり気にしなくていいので、クラウドで提供されているWebサービスを使ってみようと思います。
今回はGCPとAWSを調べます。オープンソース(MECABなど)はまた次の機会に調べたいです。

このあたりのAPIで構文解析が出来そうです。どちらもAutoML対応です。
※AutoML(Automated Machine Learning:自動化された機械学習)とは、機械学習モデルの設計・構築を自動化するための手法全般、またはその概念を指します。
■AWS Comprehend
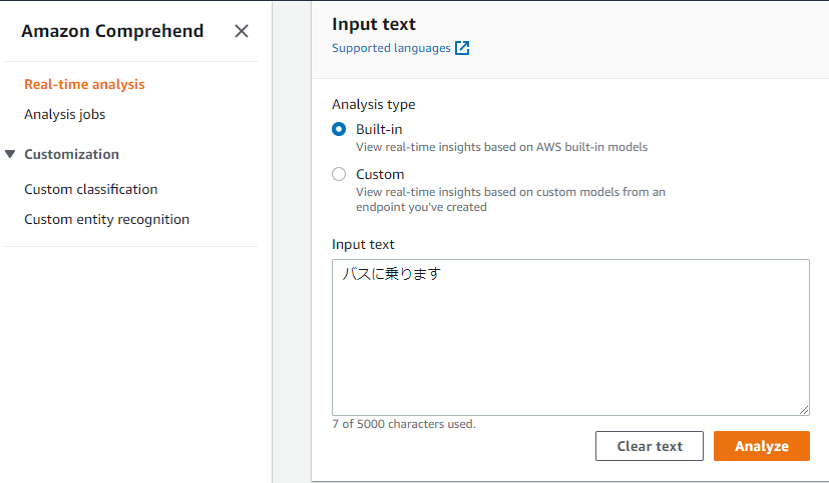
Real-time analysisが用途にあいそうです。
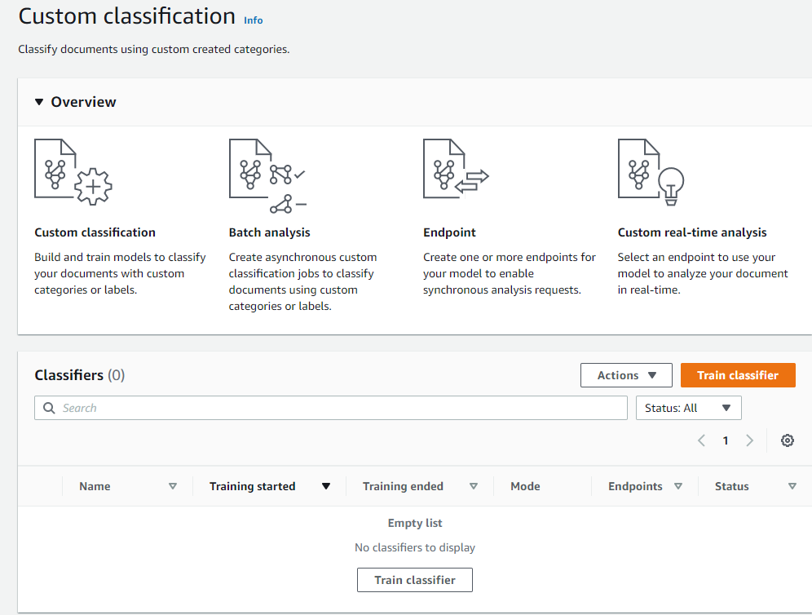
トレーニングしてEndpointのカスタマイズも出来るようです。
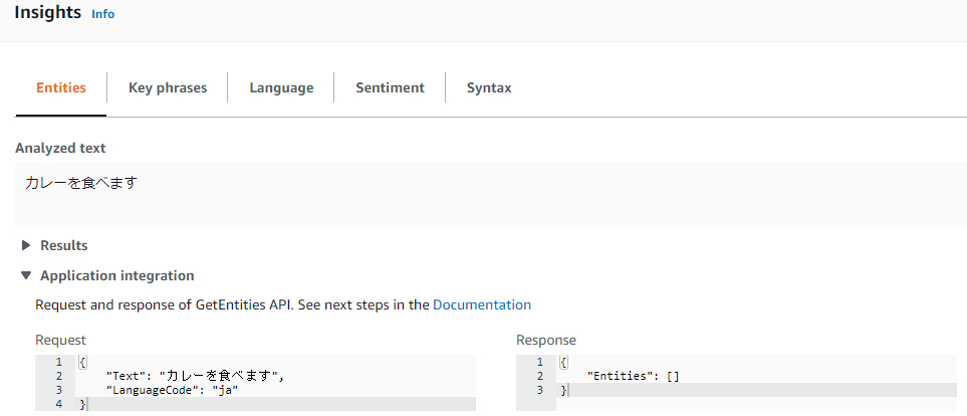
実行してみた結果、Entitiesが抽出されないです。
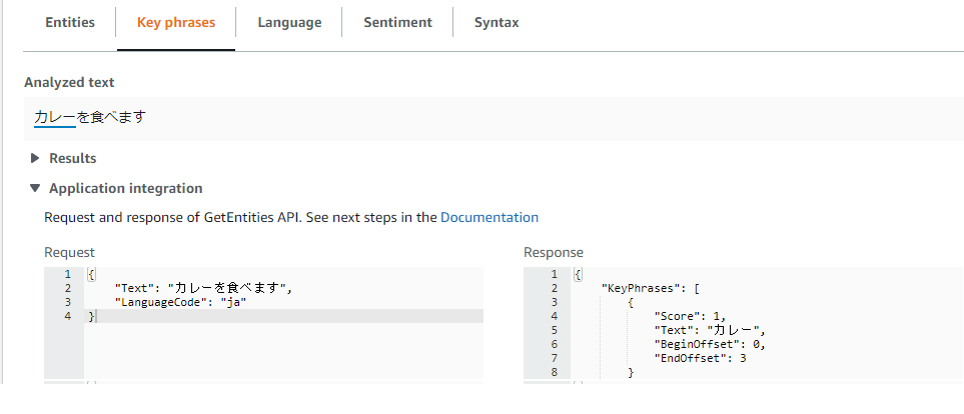
Key phrasesは抽出されました。
■Google Natural Language API
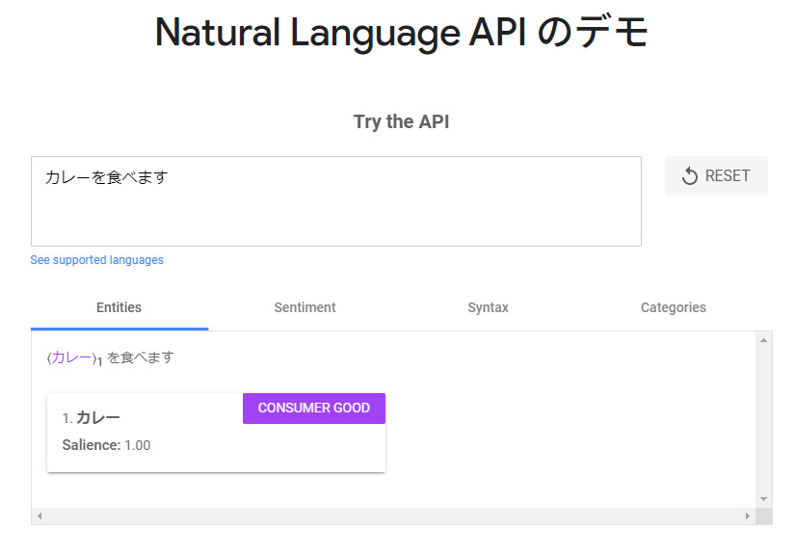
デモページで実行します。こちらはEntitiesが抽出されました。
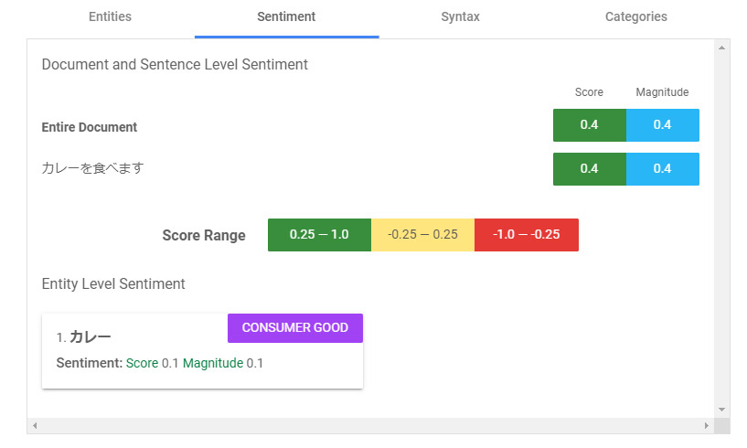
Sentiment(感情):Magnitudeが感情の絶対的な大きさ、Scoreが-1.0(否定的な感情)と1.0(肯定的な感情)の間の感情スコア となります。AWSもですが感情は概ねポジネガの表現となるようです。
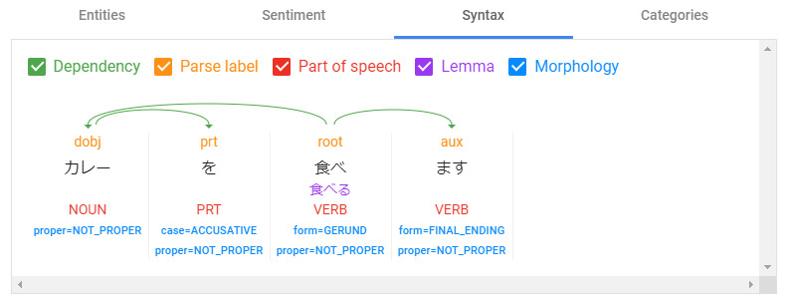
Syntax(構文解析):これが実現したいことに近いです。名詞とか動詞を選別できています。
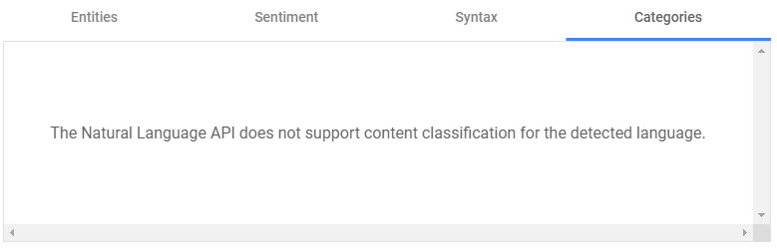
Categories(コンテンツ分類)は日本語はサポートされていないようです。
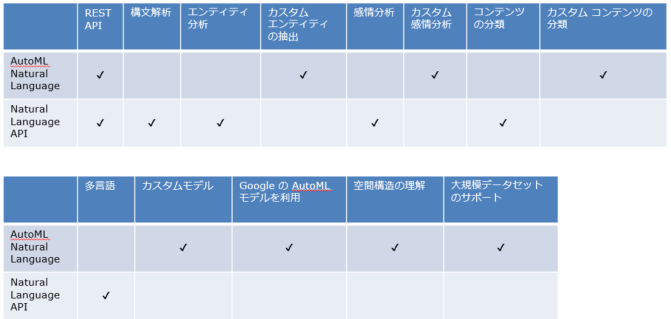
学習したモデルなどを使いたい場合は構文解析や多言語対応はしていません。今回は構文解析を使いたいのでAutoMLは利用しない形となります。
■比較結果
AWSはまだ日本語への対応はあまり出来ていませんでした。
GCP側の構文解析が用途と一致しそうです。
■料金の試算
APIに送信する 3 件のリクエストそれぞれに、800 文字、1,500 文字、600 文字が含まれている場合、1 番目のリクエスト(800)が 1 ユニット、2 番目のリクエスト(1,500)が 2 ユニット、3 番目のリクエスト(600)が 1 ユニット、合計 4 ユニットとして課金されます。
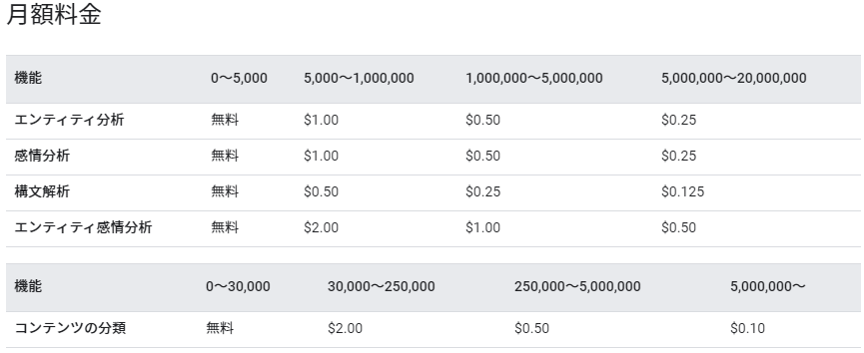
※請求月に分析されたユニットの総数に基づく 1,000 ユニットあたりの料金
1000万/1000 x $0.125 = $1250 = 12.5万円
例:男性は1日に7000語話すそうです。文(ユニット)は3,4語で出来ているので2000ユニットぐらい。3時間分ぐらい使われたとして500ユニットぐらいとします。
1万人利用で500万ユニット/日 = 6万円/日
6万円 × 30日 = 180万円/月
月額としては高めですが、人は同じ言葉を話すのでAPIの結果をキャッシュしておけば大幅に実行回数を減らせそうです。
■気になった点
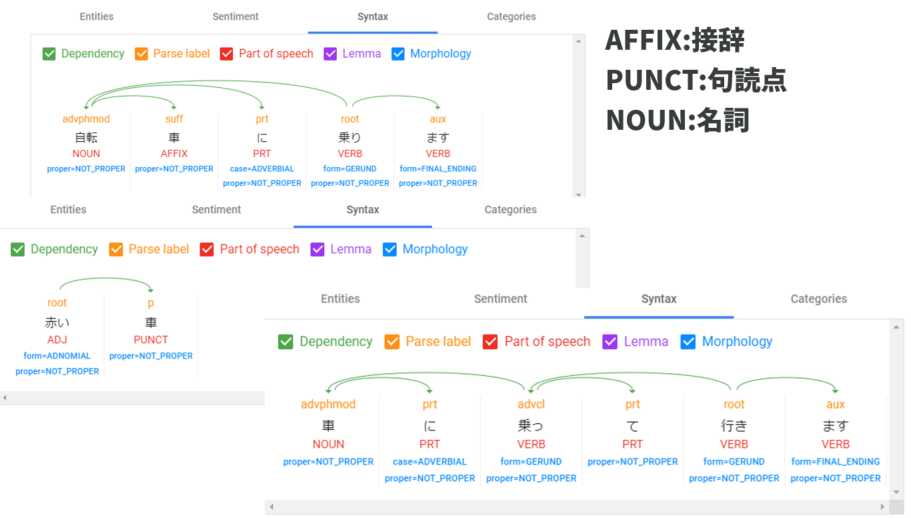
「車」の扱いが色々と変わったりします。
■終わりに
端末のOSで音声認識を行ない、クラウド上で簡単に構文解析ができることがわかりました。従量課金での料金や、API独自の解釈に注意する点はありますが、精度も上がっておりシステムに組み込みやすくなってきています。非接触での操作などが求められている現在、音声による操作のニーズが高まっていきそうです。
セガ エックスディーでは一緒に働く仲間を募集しています!
少しでも興味をお持ちの方は、お気軽にお問合せください。
最後まで読んでいただきありがとうございます。
この記事の内容について詳しく聞きたい方は、以下よりお気軽にお問い合わせください。
※記載されている会社名、製品名は、各社の登録商標または商標です。
- 文責:浅井 健一 株式会社セガ エックスディー システム開発部 課長
-
「セガ エックスディーで、xR系のR&Dを推進しています。技術はもちろん課長として数名のチームを率い、日々奮闘しています!」
共同研究・開発者 久保田 達哉(株式会社セガ エックスディー)